
Configuring an AI server and installing GPT-NeoX text generation on Rocky Linux (Centos 8/Redhat 8)
The new GPT-NeoX artificial intelligence model by Eleutherai has 20 billion parameters. Since it’s brand new, there’s no support for Huggingface yet.
Out of curiosity, I wanted to check the quality of text generation, so I decided to install it.
Like many other open-source projects, it took a few hours to fix all the issues until I could do artificial intellignce inference with GPT-NeoX, so I decided to share the steps.

The OS is Rocky Linux. It should also work on other variants like Redhat 8, Alma Linux and Centos 8 (which is EOL).
This guide is based for a brand-new server without data/software. This guide is provided “as-is”, and following it is solely at your own risk.
Server requirement
Table of Contents
The GPT-NeoX model requires at least 42GB of GPU ram, so I decided to try it on AWS g4dn.12xlarge which has four Nvidia Tesla T4, which means a total of 64GB GPU ram.
It may be possible to use Dual Nvidia RTX 3090 or a single Nvidia A6000
Initial setup
The first step it to install the basic requirements (Python, C++, other development tools):
-
sudo bash
-
yum install epel-release -y
-
yum install gcc gcc-c++ python3 python3-devel dkms kernel-devel nano wget git -y
-
yum update -y
-
reboot now
Installing CUDA 11.3
The latest PyTorch works with CUDA 11.3 (it may change in the future, so adjust the CUDA to the right version)
To install Cuda 11.3:
-
sudo bash
-
wget https://developer.download.nvidia.com/compute/cuda/11.3.0/local_installers/cuda_11.3.0_465.19.01_linux.run
-
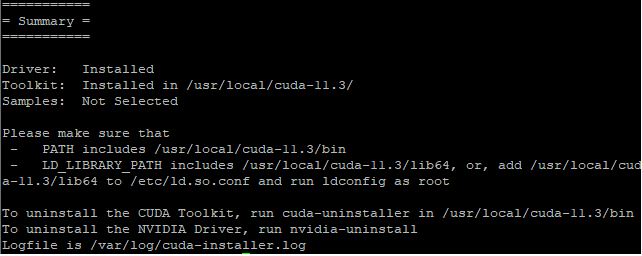
bash cuda_11.3.0_465.19.01_linux.run
In the option select screen, you can keep all selected. In case you use newer GPUs, you may need to skip the driver installation and download the latest drivers from Nvidia and install it.
If all was successful you will see the following screen:
It is possible that there’s a Nouveau driver installed, in case it is, you will get an error from the CUDA driver install, we cover in the: How to install GPT-Neo-2.7B article, how to remove it.
Installing Conda
-
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
-
bash Miniconda3-latest-Linux-x86_64.sh
Select all defaults
Setting up the paths
-
exit
-
sudo bash
-
nano .bashrc
Add the path to Cuda (/usr/local/cuda-11.3/bin/) and cuda home setting (export CUDA_HOME=/usr/local/cuda)
-
source .bashrc
It should look like this:
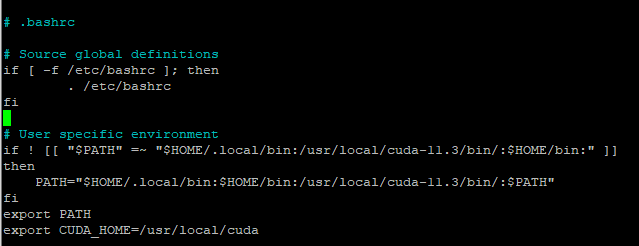
Now run nvcc, and you should get this message:
see nvcc fatal : No input files specified; use option --help for more information
Install PyTorch
When writing this guide, these are the instructions to install the latest PyTorch, going forward in time, the latest instructions can be found here: https://pytorch.org/get-started/locally/
Run:
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
Install GPT-NeoX
-
git clone https://github.com/EleutherAI/gpt-neox
-
cd gpt-neox
-
nano requirements/requirements.txt
-
Remove mpi4py. It's not needed and will cause compilation issues (you'll get fatal error: mpi.h: No such file or directory #include <mpi.h>, I tried to install OpenMI, got link errors)
-
pip3 install --upgrade pip
-
install fused kernels: python3 ./megatron/fused_kernels/setup.py install
Download the model
Run:
wget --cut-dirs=5 -nH -r --no-parent --reject "index.html*" https://mystic.the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P 20B_checkpoints
Update the model configuration
-
nano configs/20B.yml
-
Update "pipe-parallel-size" from 4 to 2
The new setting is used for four GPUs
-
nano configs/text_generation.yml
-
Change "text-gen-type" from unconditional to input-file
You also have:
"maximum_tokens": 102, "temperature": 1.0, "top_p": 0.0, "top_k": 0, "recompute": false,
You can set it to:
"maximum_tokens": 300, "temperature": 0.7, "top_p": 0.95, "top_k": 40, "recompute": false,
This is more inline with GPT-Neo-2.7B settings
Doing the text generation with GPT-NeoX
Create the source file:
echo What is COPD? > sample_input.txt
Run the artificial intelligence inference:
python3 ./deepy.py generate.py -d configs 20B.yml text_generation.yml
If all were OK, the output would be at: sample_output.txt
Observation
I tried to use the interactive option, but it crashed with a bug most often. That’s why I changed to file mode.
The bug was something about shape issues, not my job to debug and fix it 😊
Final thoughts
I hope when this model is ported to Huggingface, it will be easier to work with and have fewer bugs.
Big respect goes out to the EleutherAI team for advancing the open source AI research.