
How to create your own SEO tool – The detailed guide
Having any type of digital product is great, you can sell it. Usually, there are no costs associated with delivery, no production costs, and no warehouse.
Implementing your own idea, SEO or otherwise is a process that has many hardships, but can have immense satisfaction. If you reached this page I assume you know what SEO is.
You probably used and still using an SEO tool, and may wonder “How could I build my own SEO tool?”. Maybe you want to sell it as an SEO SAAS, SEO Software, or use them in house for DIY SEO Project.
Then you are in luck, as this article will cover How to create your own SEO tool, and will guide you a step by step on the high-level design and requirements in the process of Development of SEO Tools. You can call this article: DIY SEO Tool.
Types of SEO tools
Table of Contents

SEO tool is a broad definition, and there are many niches you can get into, each with its pros and cons, this article will outline the most typical niches, and summarize what how to build your own SEO tool:
- Backlinks explorer tool.
- Keyword explorer tool.
- Rank checker tool.
- On-page SEO Audit tool.
- Brand mentions tool.
How does an SEO tools work?
Before going into the details of how to create your SEO tool, it’s crucial to understand how SEO tools work, the tools (any SEO tool), has multiple stages:
- Acquire the data from various sources: Public internet data, clickstream, 3rd party data, SERP.
- Store it on a database: MySQL, PostgreSQL, Redshift, custom database.
- Process the data using specific algorithms to get insights from the data: Domain rank, which keywords a site is ranking for.
- Show the results to the end-user via GUI or provide the results via SEO tools API.
How to create backlinks explorer tool
In this section, we will go over what does a backlinks explorer tool does, what are the parts needed to develop such a tool, and how to develop each part.
What is a backlink explorer tool?
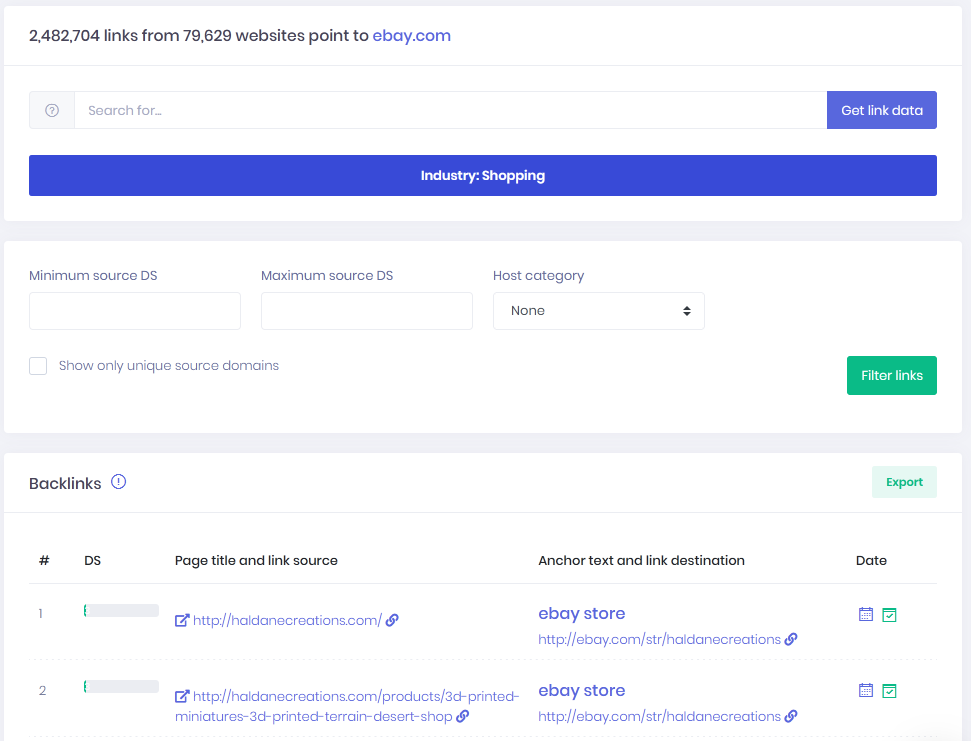
Backlinks explorer is a tool that allows the end-user to:
- Learn who links to his site, and how
- Discover where the competitors are getting links from
- Learn where sites link out to
- Help in the process of domain vetting for:
- Purchasing live domains
- Purchasing expired domains
- Deciding where to do guest posting
To summarize all the options, the goal of a backlink explorer tool is to help with link building and/or help with link disavowing.
How the backlink explorer tool works?
Three parts make the backlinks explorer tool:
Crawler
A crawler is a software that retrieves the content of public web sites, the crawler can be small, for small projects and low amount of webpages, or enterprise-grade to crawl the entire Internet, just like Google’s crawler, which is the largest that exists.
The goal of the crawler is to scrape the data on the web page. Once it has the data, the crawler or another component can parse the backlinks.
Database
Once the crawler got the links, it will store the links in a database. The database allows for fast retrieval of the data. The size and type of the database are dependent on the amount of data crawled, for a small project a single server can do. Still, for Internet-wide crawls, there’s a need for a distributed database, most likely with in house customizations.
GUI
For backlinks explorer tool, the product is mostly SAAS (Software As A Service), which means the GUI is web-based. The GUI should be intuitive as there’s many data point and the end-user should understand rather fast how to access the data he’s looking for.
How to create backlinks explorer tool
How to create backlinks crawler
There are numbers of open-source crawlers available, written in different languages. When we started with our crawler, we had two programmers build a Python-based crawler, and it was able to crawl ten pages per second on a VPS with one core, taking 100% CPU.
We had someone build a C based crawler, and it was able to crawl 100 pages per second on one core, taking 1-3% CPU.
So, choosing the right language of the crawler would impact the hardware selection, it’s a tradeoff between an expensive programmer and expensive hardware.
The essential traits of a crawler are:
- Fast and light, use as little CPU as possible per downloadable page.
- Honours robots.txt, to avoid abuse reports.
- Able to parse sitemaps to get new data.
- If it’s enterprise-grade, then it should be distributable.
Building a crawler with Python
Python is an easy to learn language, with a rich ecosystem and libraries; it cost us 100$ to have a freelancer build a basic crawler with Python and Scrapy. Also, Python has many libraries to parse the DOM and get only the essential elements like Page title, Page description, links.
The development would be fast and not too expensive; the downside is the need for more hardware.
You can download the scrapers/crawlers that was built for us: Python scraper 1, Python scraper 2
Building a crawler with Libcurl
Libcurl is the leading development library for HTTP/S communications, it also supports asynchronous connections, for single HTTP/S requests it’s straightforward and easy. Still, to write a crawler, that’s more complex but doable.
A preferred language would be C or C++, and you will also need some libraries to parse the HTML to extract the links and other information from the page.
You can download the scraper/crawler that was built for us using C and Libcurl: c scraper
Build it all yourself
Our experience shows that for core technologies that need to be highly customized and built for speed, it’s better to write it yourself, we assume you have a very experienced programmer up to the task, just like we have in house.
We developed our own crawler, written in C with BSD sockets and OpenSSL, our own HTTP and HTML parsers. Writing your own crawler allows for the best performance, but the cost was extra development time.
Bandwidth consideration
Bandwidth cost is also an essential factor; some hosts like OVH provides unmetered bandwidth based on the port speed (100MB, 1GB).
Some hosts like Amazon charge for the actual bandwidth, and you may end up paying more for the bandwidth than the hardware.
The bandwidth criteria mean you might need to use a host that requires more knowledge and expertise but gives cheap bandwidth over using an easy to use as Amazon.
How to build a database for backlinks

Once you have the data, it’s time to store it. How much data do you plan to have? Ten billion backlinks would take 4-5 Terabyte of database storage, for comparison the competitors (Ahrefs, Semrush) offer a database of over 1 Trillion backlinks.
The issues with open source databases (MySQL, for example) is that after 50GB in storage, the insert speed degrades exponentially. For backlinks database, there’s a need for sustained insert speed, for our needs it was about 50,000 inserts per second, and after 50GB of storage the speed started to go down, at 200GB of storage it was so slow, it was unusable.
Amazon Redshift
Amazon Redshift database can be scaled easily to have a large storage, and shouldn’t have the same problem the open-source solution has, but 10 Terabyte of space would cost 30,000$ monthly on SSD storage.
Clustered database
Some hosting providers offer clustered MySQL or PostgreSQL out of the box. A clustered solution can get around the insertion speed issue if each node is limited to 200GB storage.
The problem is that the clustered solution costs 10,000-20,000$ per month for ten Terabyte of storage, depending on the hosting provider.
Commercial database
There are commercial databases that can handle this load, like Oracle database, we don’t know what the price is, Oracle database is an enterprise product, it may not be suitable for startups.
Percona MySQL database
Percona is a company that specializes in database optimizations, and they have a custom version for MySQL, MongoDB and PostgreSQL. We wrote a long article in Quora about the database ordeal, and someone asked if we tried their Tuko engine, I didn’t. So it might help, we never tested it.
Custom database solution
We decided that paying 10,000-20,000$ per month for a database is too much. Besides we haven’t made a single dime yet, is not the way to go, we don’t have VC money, and that amount puts great pressure on finances.
We decided to develop a custom database that can handle the insert and select load. We can host it for 350$ monthly, but it took us two years to build it, so we traded time for money.
You can read our article about which database we use (hint: we built it), it covers in more detail about the limitations of current databases and how we solved it.
Integration and GUI for backlinks tools
Now that you got the database and crawler, it’s time to integrate and make sure you build a friendly GUI so people can see their link building efforts.
For web SAAS, there are several languages people use: PHP, NodeJS. We use PHP and a custom HTML theme; we cover more about GUI development later in this article.
Our backlinks API
Our API allows to get all the backlinks information regarding a site: Backlinks, Outlinks, Top pages, Referring domains, Referring classification, Top anchors and more.
Our API can be used for building:
- Free SEO tools as lead magnets.
- Commercial SEO tools.
- Internal research tools for link building.
- Other Internet marketing tools.
Check out our Backlinks API details.
How to create keywords explorer tool?
What is a keywords explorer tool?
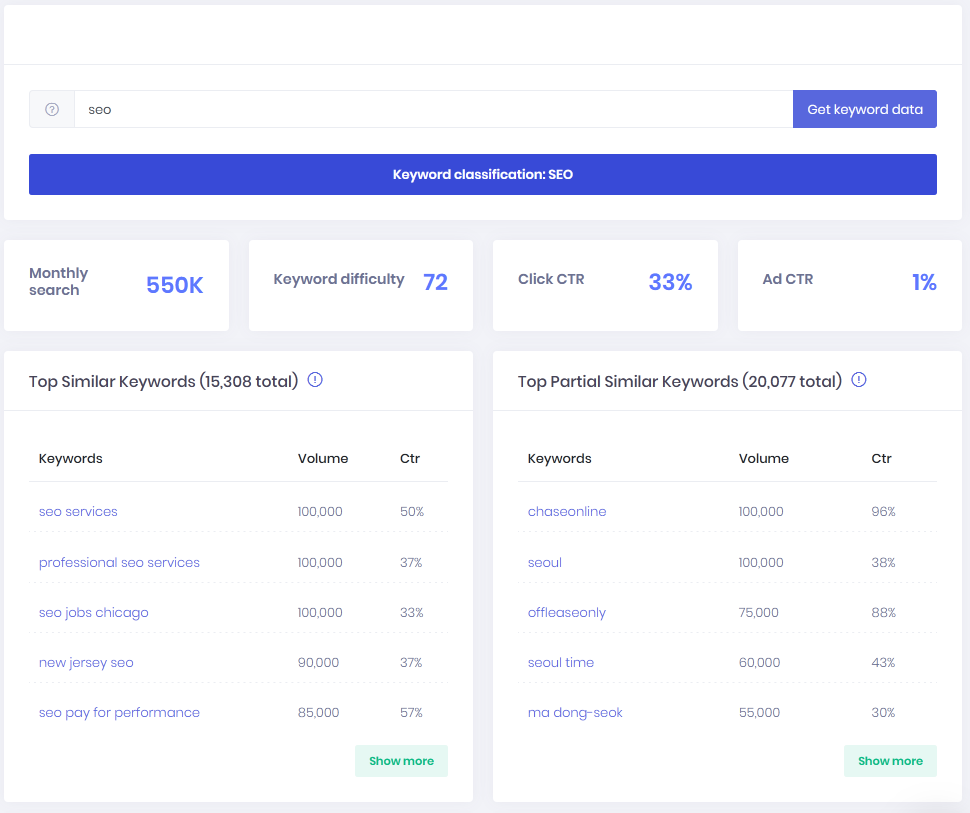
A keywords explorer tool allows the end-user to gather keyword ranking information about his website, and the competitors, this allows you to know:
- Which keywords does his site ranks on, and which position?
- Which keywords do the competitors rank on?
- Keywords opportunities and ranking difficulty.
- Keywords search volume.
- Keywords PPC costs.
- Long-tail keywords.
- Similar keywords.
A keyword explorer tool also helps with keyword research. Keyword research is crucial to any content marketing campaign. For example, we wrote a few blog posts without doing any keyword research (Like this one), we just wrote what came to mind, but since the post didn’t focus on anything the user searches, it gets about one hit per month.
BTW we wrote this paragraph in Nov 2020, and we will revise all of our content with proper keyword research, trying to salvage the content.
Why should someone use a keywords explorer tool?
A keyword explorer tool is used mostly for SEO and PPC:
- Research which keywords to focus on, when writing articles.
- Discover easy to rank keywords.
- Discover cheap PPC keywords.
- Keyword search volume tool.
How does a keywords tool work?
Keywords explorer tool has several components:
Keywords explorer scraper
The scraper is the component that gets the data from the search engines (mostly Google, but some products supports more engines), parses it and make it ready for storage.
Keywords’ search volume data
Keyword search volume data is static data that is displayed next to the keywords, and it might also contain keyword ranking trends.
Keywords’ PPC data
Keyword PPC data is static data that is displayed next to the keywords, and it shows the average cost for Google AdWords PPC.
Keywords explorer database
The database stores the data in the previous sections:
- SERP results.
- Keywords’ search volume data and trends.
- Keywords’ PPC data.
GUI for keywords explorer
The answer is almost the same as for backlinks explorer tool the exception is that keywords explorer is only SAAS and not a local software. So with SAAS, the GUI is web-based.
How to create keywords explorer tool
How to write a scraper

Type of IPs
A scraper gets the search engine results. Google and the other search engines don’t like it, so they employ Recaptcha to stop the scraping. Even if someone is using anti Recaptcha methods, eventually Google will block that IP anyways.
There are various methods to scrape Google successfully:
Datacenter IP
Datacenter IPs are easy to come by, you can spawn a VPS starting from 2$ on low-cost providers, to 5$ on a leading provider.
The problem is – Google knows that too; it will display the captcha after about 100 requests.
There can be several solutions to this problem:
- Replace the IP every time the IP is blocked, and most VPS providers have an API to do so, check the provider TOS before doing that, see that this is allowed.
- Make a request every x seconds, depending on the results you ask for, the more results, the bigger the x. The problem here that you must maintain a large number of proxies.
Using residential IP
Since Google knows the IP came from a residential IP, it will not block the requests as long as you wait a few seconds, the problem is, how to get such IP?
If you live in the place, you plan to scrape the results from, and then you can install several connections and use them, the problem is, for an extensive keyword database, this will not scale well.
Another solution is to use a residential IP provider like Luminati, and the problem is the price, the charge per bandwidth, which makes the operation very expensive.
Which language to develop the scraper?
Unlike the backlinks crawler, the scraper doesn’t have to be very efficient, so Python or even PHP can be the right choice.
If there’s a need to render JS, then using headless Chrome or headless Firefox will be preferred.
Where to get search volume data?
Clickstream data
Clickstream data is collected from real users, and it contains every URL the users visited and every search phrase they searched.
The search volume of every keyword can be deducted based on the number of panellists that are part of the clickstream data in a specific country.
This data allows us to get an estimate of the search volume because it’s only a part of the actual users searching. Also, the way this data was collected affects the results.
When an Antivirus provides the clickstream data (like it was with Avast), it means the data represents the way that end-users that installed Avast behaves, it may be different from other types of end users that wouldn’t install Avast.
If the budget allows, purchasing clickstream data from multiple sources will allow for better estimation of search volume.
Search volume from API
Some companies such as ours are selling search volume metrics with an API, and there are two types of commercial API usage:
Internal API usage
When the data is used internally, which means it’s not displayed publicly, it can be used for the company’s internal needs, or to show private reports to SEO clients.
This usage should be cheaper than white label usage.
Whitelabel API usage
Is used when developing a public app or SAAS and you want to show 3rd party data, the best example would be Neil Patel’s Ubersuggest, he publicly revealed his monthly spending on the tool. Part of the expenditure is for development and role for the data.
Obviously, this data is more expensive, and most companies will perform due diligence before providing such API functionality.
Google API
Google offers an API that provides PPC prices information, search volume data. It’s all the data that is available via their Keyword planner tool. They provide the API after a vetting process, and the API can only be used for specific goals.
Where to get extra keywords
Google says that 15% of all searches are new, which means that even if you get clickstream data, it will not include all possible keywords (you can read more about it here).
On this blog we have some articles that ranked on keywords that our tool and other tools show no searches. When doing keyword research, keywords with “zero” searches may have enough search volume never the less.
Luckily we can get most of this data from Google itself (also from Bing and Yahoo), which you are already doing with a scraper.
Related search
In the bottom of each search results page, there are a list of keyword suggestions related to our searched keywords.
People also search.
Some pages show another pane with people also searches, which gives even more keyword options.
Google Trends
In Google Trends, there are two options:
- Related topics – Shows related topics to our keyword, for example, related topics for “keyword research” are Niche market, content, Affiliate marketing.
- Related queries – Shows what other people were searching for in relation to the keyword. It’s another data endpoint to the related searches in Google web search.
Google autocomplete
Google autocomplete suggestions helps the searcher do a search based on the previous searches, for example, let’s say a user enters “keyword research”, Google will add options based on past searches, for example, tool, Google, for SEO. It will not add keywords; however, without any meaning for the search like a cat, not that you can’t search: “keyword research cat”, it just that it has less meaning.
Google Search Console
Some products like ahrefs and Ubbersuggest request access to the Google Search Console, they then use the keyword data provided by Google to show improved keywords data.
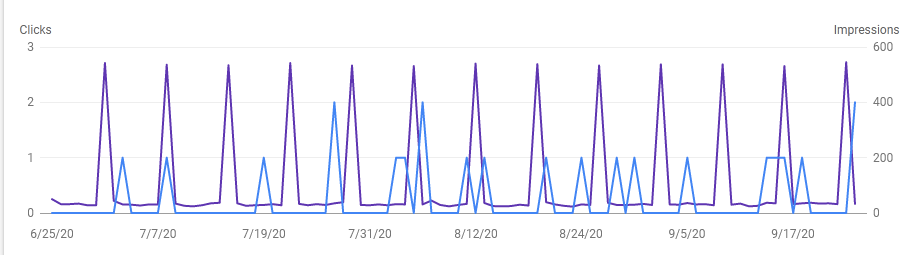
One thing to consider is that for low search volume keywords the bots can skew the data, as you can see in the graph for one of the keywords we are ranking for, one the same day of the week a bot searches Google for this keyword.
Database for keyword explorer
Unlike the backlinks explorer, the data is not too big, and the insert speed requirement is low. One or two instances of MySQL would be enough; the challenge here is the sorting based on search volume, searching for similar keywords, and searching for similar phrases. For example:
How to sort big data
A site like eBay is ranked for millions of keywords in the SERP. When showing eBay’s result (or any other results), they are sorted by the search volume.
It doesn’t matter if the applications display five results, or a hundred results, the database will have to fetch all the results (millions) and sort the result before providing an answer.
The speed will depend on the database’s hosting computer performance, and number of jobs the database is currently doing, but even on an idle server, this will take at least a few seconds which can make the site look slow.
The way we solved it is to precompute the sorting. We developed a multithreaded C++ program to precalculate sorted results, which means we have a table that holds all the keywords for the sites, and the search volume is already sorted.
Using this method – fetching the results is almost instantaneous.
How to sort similar keywords
Similar keywords are keywords that contain a seed keyword, for example, for the keyword “seo services”, has the following similar list of keywords: professional seo services, affordable seo services, white label seo services reviews.
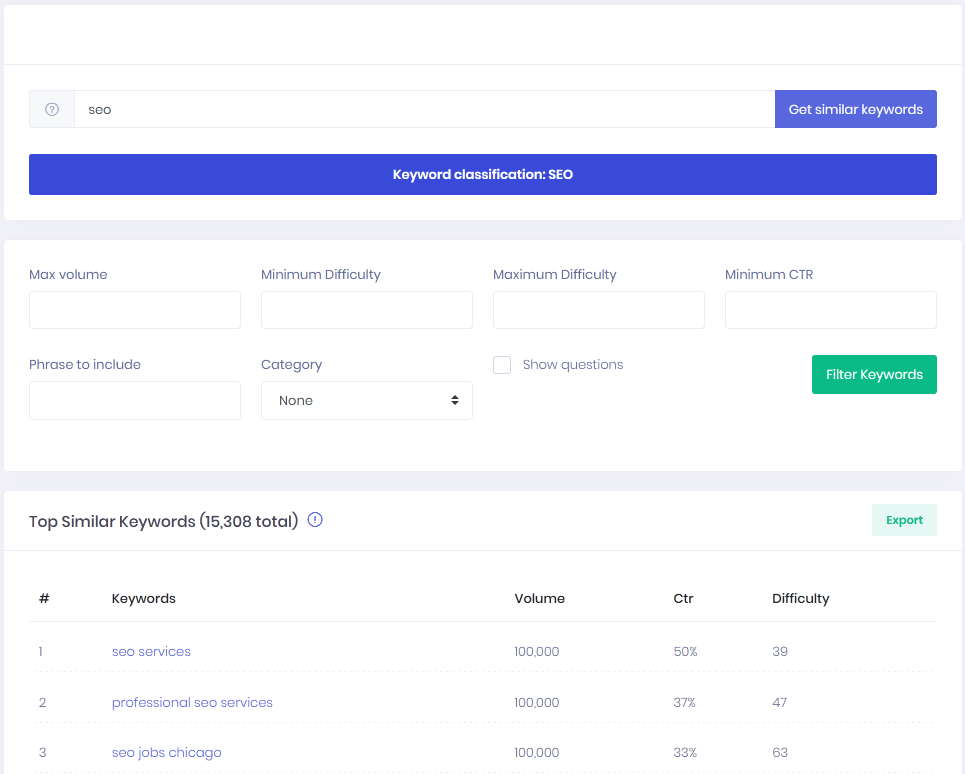
We have 270 million keywords just in our primary database, doing a similar search even with full-text indexes can be time and resource consuming.
The way we solved it, we used a C++ program (again) with Aho-corasik algorithm to precalculate those keywords lists, and then we store it in a table.
Aho-corasik is an algorithm that allows doing a fast search on a string; in one pass, it finds all the keywords in our dictionary.
Even with that algorithm in place, it takes the program up to 48 hours to go over all the keywords, think how long it would take to do it in the database level.
The Aho-Corasick version we developed and use can be downloaded for free: Open source Aho-Corasick.
How to sort similar phrases
Similar phrases are phrases that contain the seed word, just not in the same order, for example, the seed keyword: “free mac pdf editor”, has the following similar phrase list:free pdf editor for mac without watermark, adobe pdf editor mac free, free pdf editor mac download, pdf editor mac free online software.
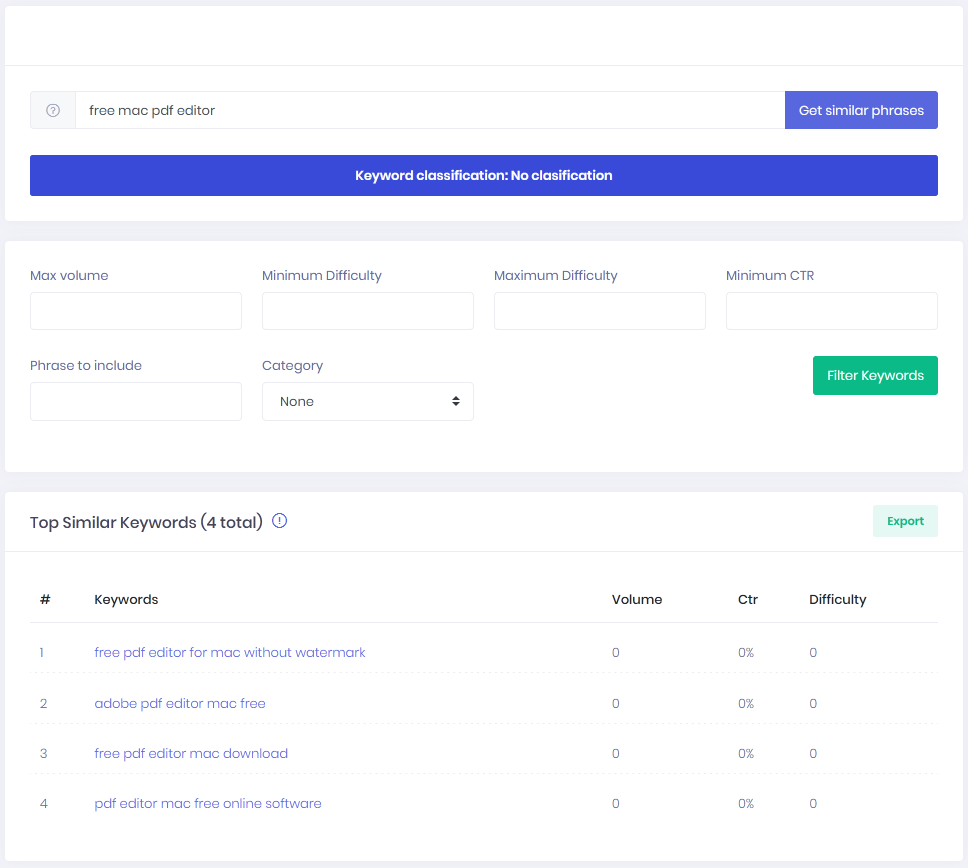
I’m not sure it’s even possible to design a database query to fetch such a list, the way we have done it, is use the same program from before, but this time we take each keyword and build all the permutations, and then we search those permutations.
When we first ran the program, it was “stuck”, when looking deeper we found the problem, a phrase with 12 keywords, generates 479,001,600 options, which will take two days just to search.
We had to limit the phrase building to 9 keywords, which generates “only” 362,880 results, we put this on a 40 logical thread server, it takes a month to go over all the keywords.
Keyword difficulty tool
Part of a keyword explorer is to gage the keyword difficulty, and each company has its own way to calculate this score, at the end all the numbers are estimates.
The data that can be used to calculate the keyword difficulty is:
- Website Page rank (also referred to as domain authority)
- Number of links (unique or total) to each link in the result
- On-page factors
The way we calculate it is by creating the average of the page rank of each site in the results; in the future, we plan to look at this again.
Integration and GUI for backlinks tools
The GUI is always the same for all tools; later in the article, we provide a detailed explanation on how to write GUI.
Our Keyword API
Our API allows to get all the keyword information for specific geographies: Keyword search volume, similar keywords, related keywords, also ranking for keywords, and more.
You can use our API to build:
- Keyword research tool
- Augment on page content creation tool with keyword data
- And more
Check out our Keywords API details.
How to create a keyword position rank tracker
What is a keyword position rank tracker?
A rank tracker is a tool that tracks a site rankings and keyword position in the search engines. It will:
- Track keywords across different geographies.
- Track keywords in specific cities which is needed for local SEO.
How does a keyword position rank tracker work?
Rank trackers are search engine scrapers that use proxies or other means to use different IPs to scrape the SERP in a specific geography or cities.
How to scrape from the right geography
When using a proxy to scrape Google, the geography is the location of the proxy, so if our proxy is in New York City, the results would be for New York City. Furthermore, if we also plan to scrape local results like GMB or entries for local services such as plumbers near me, then the result would be from the zip code of the proxy.
Changing geography
Since people want to track their results from various geographies, there are multiple ways to do it.
Proxy server at the location
The easiest way is to have a proxy at the location we want to track from, it’s the cheapest, but it’s not scalable since there are 90,000 zip codes in the US alone, so it will allow supporting only for a limited number of zips.
Residental proxies
An excellent residential proxy network should allow choosing a proxy at the zip code. The drawback is the price, and it’s very expensive.
Telling Google your geography with UULE
There’s a search parameter called UULE, which allows you to tell Google exactly from where to search, so with one proxy server, you can scrape every geography.
There are some drawbacks to this way:
- If you use completely different geography, for example, a proxy in India and UULE pointed to the USA, you will get some results for sites from India with local sites from the zip code you chose.
- Some people claim that UULE is not as accurate as a real proxy from the zip code and the UULE search radius is different or not precisely where it should be.
- The proxy will get banned faster when using this flag.
For more information about UULE you can read the guide here.
How to build a keyword position rank tracker?
The rank tracker should be the easiest tool to create, that’s why there’s so many out there, the entry barrier is low.
Because there’s little data, any database will do, you can go with MySQL.
Since you need to track keywords position across various geographies, using a residential IP proxy provider makes sense since the number of tracked keywords is tied to the number of subscriptions, the cost of the IP provider should scale well with revenue.
The “crawler” section on similar keywords tool in this article covers how to write a SERP scraper which has the same applicability to the rank tracker scraper.
How to create a on-page site audit tool?

What is a site audit tool?
Site audit tools are used to detect on-page SEO issues like:
- Find Broken links.
- Check for missing or incorrect robots.txt.
- Discover missing or incorrect sitemap.
- Check for internal linking issues.
- Detect missing meta description tag.
- Find incorrect usage of header tags (for example, H1).
- Discover duplicate content.
- Generate a sitemap.
- Check for missing hreflang.
- Technical SEO issues.
- And more.
How does a site audit tool work?
A site audit tool works by crawling the site it audits and analyzing the link structure and meta information on each page. Once it has all the data, it processes it to show the auditor the relevant information to fix.
How to build a site audit tool?
The core component of such tool is the crawler, the first decision would be whether that crawler is based on SAAS (the crawler is hosted at your servers) or the crawler is a downloadable software.
Crawler as a SAAS
Unlike the crawler for backlinks tool, this crawler usually needs to crawl less data, which means you can get away with Python-based crawlers, which will speed up development time.
Once you have your crawler in place, you’ll need to analyze all the factors mentioned, and Python has many libraries to do so, so a fair Python programmer should do the job rather easy.
All the data would go to a database since there’s not a lot of data, a single MySQL instance would do the job.
On Code Canyon there are several scripts to do SEO audit, they can be used as a base for the final SAAS software and save development time.
Script language or C++
When developing the backend for the on-page audit tool, the selection of the development language should fit the market size.
If the amount of web pages scanned is small, a scripting language like Python or PHP would be a good selection.
If you plan to have many users and many sites scanned, the technical SEO analysis and other on-page analysis will tax your servers, and this means you might need extra servers.
In this case, the tradeoff is between development speed and hardware cost; there’s no right and wrong answer.
Crawler as a download
The main decision, in this case, is which OS to support, if the plan is to support multiple OSs, you should use a development language that is not OS depended like: Python, Java, NodeJS. The drawback is the need to install the development language runtime locally, which on some computer can fail for various reasons.
If the software is meant for a single OS, it can be written in C/C++, with minimal dependencies, this will allow for a higher success rate when installing the software. Also, a good programmer can write C/C++ code that will port easily to Linux/Mac if it’s known upfront.
For a local database, you can use SQLite, which is the gold standard for local databases (I wouldn’t try to install MySQL locally, that would lower installation success rates)
Javascript rendering
Some sites are using Javascript to render their content, which means that if you scrape them with a regular scraper, it will take some or all of their elements.
The solution is to use Headless Chrome, which can be invoked from the command line or controlled via a package called puppeteer.
One thing though, Headless Chrome mentions it’s headless, it does so in the user agent, on our main site we block headless browsers.
Using a script to create a Site Audit tool
Sometimes you need to have a site audit as a lead generation, and it doesn’t need to have all the bells and whistles.
You can find ready-made scripts that do basic site audits on sites like Code Canyon, and you can search for PHP SEO. You’ll find many SEO related scripts.
Keep in mind that we don’t endorse any script, and you should do your due diligence before using any script.
How to make an SEO tool website (small SEO tools)
There is numerous type of sites that provide many small utilities for SEO, like:
• Image conversion
• Image editing
• Various keyword tools
• Various backlinks tools
• Plagiarism Checker
• Article Rewriter
• Grammar Check
• Word Counter
• And more
The site smallseotools.com has an Alexa rank of 2000 (Checked May 2021), which means it gets a lot of traffic from SEO-oriented users.
Creating and promoting such site or adding such features to an existing site can add valuable traffic to any SEO venture.
The easiest way to achieve this is, like we mentioned before, to go to a site like Code Canyon and search for PHP SEO. They have many scripts that allow you to deploy a site similar to smallseotools relatively fast. (remember we don’t endorse any script, and you should do your due diligence)
Some of those sites are also affiliates to the SEO big sites (for example, Semrush). That’s why they can show data such as Backlinks data and Keywords data. If you want to show such data, you could develop your own, use an API, and be an affiliate in exchange for data.
Other tools
Other SEO tools are not mainstream. Obviously, we can’t cover how to create every SEO tool, for example, our SAAS has built-in URL Classification, it allows for better domain vetting, we integrated our URL Classification SAAS with the SEO SAAS.
I could theorize for most products the core principles shown here for the other tools:
- If the tool needs fast data additions, it needs a distributed database solution which is expensive, or a custom solution which is costly to develop.
- If the tool uses AI, you can use a premade dataset from GPT-2, or use a library by Huggingface.
Which hosting provider to use

When developing this kind of tool, you must have an experienced sysadmin, so the answer is written with that assumption in mind, besides for a project at that scale, you must have someone that experienced, or you’ll end up paying a premium for mistakes.
Database hosting provider
We host our custom database at Hetzner, from our experience Hetzner is the best-dedicated server hosting company we worked with. We had a hard drive replaced within 5 minutes; the entire motherboard replaced within 30 minutes.
In general, a dedicated server will be cheaper and faster than any cloud VPS, for example, we use a server with 12 logical threads and 256GB that costs 80$ per month, getting an equivalent in the cloud costs around 1000$ per month.
If you plan to use a distributed database, you can go with a provider that has a built-in option to deploy such a database, like DigitalOcean. You can also use Amazon Redshift, keep in mind it may be more expensive than going with the distributed database.
If you feel that your team is highly technical and able to deploy a distributed database by yourselves, you can save by using a cheap dedicated server host like Kimsufi.
VPS for proxies
For VPS, you can go with the big players: DigitalOcean, Linode, their smallest VPS costs 5$. Amazon LightSail smallest VPS costs 3.5$ and we’ve found some good providers that you can get an IP for 1.75$.
There are smaller players which offer 2-4$ VPS, the more technical your team is, the more leeway you have with picking up the providers.
Buy complete IP ranges for your proxies
Some hosting providers offer to buy or lease an IP range. For example, OVH sells a class C (256 Ips) for a one-time price of 756$.
But, most of those ranges come from countries that sold their IP pools because of the IP4 shortage.
For example, you could buy a range claimed to be in USA, but in reality, the IP4 range belonged to Pakistan before and not all of the IP geo providers changed it to the USA.
Furthermore, it’s possible that all the IP GEO providers changed the detection of the IP to the USA, but Google didn’t.
It means you’ll need to check with each GEO IP provider and even with the vendor how the IPs are identified. We refunded a few deals just because the IP wasn’t identified correctly.
Front end hosting
Unlike our recommendation to use dedicated servers, with the front end a VPS might be a better pick, the reason is, it’s easy to backup, deploy more instances on the go, and usually, at the start, there’s no demand for high performing hardware.
In later stages, when the traffic is high, you can go with a dedicated server and various CDN solutions like Cloudflare, that will help with the high traffic.
It’s essential to make sure your website loads fast from the geography of your end-users; you can use a tool like Pingdom to benchmark your site.
Which development language to use for the frontend?
Here at SEO Explorer, we love PHP. It’s very similar to C/C++, which is the language we use for our backend.
At the beginning we thought if we should use a framework, we read the reviews, and decided against it, the tipping point was that the inventor of PHP – Rasmus Lerdorf was against it, as written here.
Some people will swear by PHP frameworks. It’s a matter of opinion, and there’s no right or wrong answer.
For the design itself, we use a theme called Metronic, which saved us a lot of time since the theme is responsive and automatically supports desktop and mobile browsers, we paid about 80$ for it. Still, the saving in development costs was crazy.
The good thing about HTML themes is that you can add any development language to it, PHP or others, which gives excellent flexibility.
There are many other good themes you can purchase at Themeforest for a low price.
Which framework to use for your blog?
For our blog (the one you read now), it was a no brainer, and we use WordPress, it’s the most supported blogging ecosystem, you can’t go wrong with it.
One dilemma we had, for SEO, should we use our domain as a standalone subdomain or as part of the domain, we decided it should be part of our domain for higher domain ranking.
Should you build your own SEO tool?
If you reached this point, you should have a high level of understanding of what is required for every tool.
Some tools will be cheaper to develop, some tools require many servers and programmers, and you should research the tipping point between using 3rd party SEO API and development of SEO tools.
Building your own SEO Tools is never free, and the time spent on SEO tool development is a time you are not reaching the market.
In our case, our business is selling SEO tools, so it made perfect sense to develop it, but if we were an SEO agency, we would use existing tools or data.
Summary
It’s possible to develop your own SEO tool or DIY SEO, each type of tool has a different entry barrier, some are very hard, some are easier.
There’s an option to speed it up rather than build your own SEO tool– white label SEO API. We provide an SEO API that is available for private or SEO Whitelabel use case that supports:
- Backlinks checker API.
- Outlinks checker API.
- Keywords search volume API.
- Similar keywords API.
- And more.
It’s possible to integrate our SEO API into an existing solution or build a new solution.
I hope you enjoyed our article about do it yourself SEO software.
Last updated: 10th June 2022
Thank you for opening up on how these tools are built.
What is your recommendation for SERP scraping at bulk?
I know that you mentioned that Luminati is very expensive. Currently I know Python + REST APIs atm 🙂
Best regards,
James.
You have to spend some cash to do it, it’s either:
Hi,
I want to build my own SEO Tool. Can you help me for that?
hello thx for you sharing..
would you mind to share recomendation ebook c++ to build seo tools ?
and again thx you very much
The question is too general, which tool exactly do you want to build with C++?
i just know c++ a little, I have no idea where to start and with what tools to build seo software, i like to build my self.. coz ahref and semrush its too expensive to me. so I beg you to recommend what books I should read
thx you sir.barak
i need keyword tool , indexing tool and backlink tool..
To build such tools with C++ you need to have good knowledge of the language, further more I can’t say C++ is the right choice 100%. Since you just want an alternative to existing tool, it would be better to use a cheaper tools, there are many good tools which charges 10$ per month for usage, unless you want to sell SEO tools, don’t try to develop what you can buy.
what language would you recommend to make such tools?
The one you can deploy successfully.
In general, all SERP scrappers, you can use: Python, NodeJS
Parts that need strong computation speed: C++
Frontend, so many options, what ever you’re comfortable with
Hey, can you tell us how to create a group buy SEO tools website?
As a tool owner I’m against group buys. It’s true that some tools are expensive, but there are cheaper alternatives that are as good as.
Thanks for the Info
Supper, thank you for sharing us from msmp technologies
Great blog, thank your sharing us.
Thanks for providing these amazing SEO tools. these tools are beneficial for my web
Thanks for sharing the info
I was able to create my own special tools and quickly archive access to 100 pages from Google in just 40 seconds and then send them to mysql via php cloudflare worker
It is a nice post to learn abot kw site. Because i want to create a kw site in wordpress
thank you for your post, i think it’s not easy to make an seo tool
Thank you for opening up on how these tools are built.
Very nice guide to build your own SEO Tools easily.
How much will it approximately cost to make my own keyword research tool and database and run it ?
I’ve seen keyword databases goes for 30,000$ only for the USA, try looking around, you might find it cheaper. But it’s not cheap.
The development part, it depends on who’s doing the development, is it you, or is it someone else, also what is your experience with programming.
If someone without programming knowledge tries to do it, the budget should be three times as much as a programmer.
My estimation is around 30,000$ for the non programmer.
Thanks for sharing this knowledge with us. Can you tell which language will be used to create Complete SEO tools like SEMrush or Ahrefs?
It depends on your programmers abilities and requirements, do you need a complex database backend? an efficient scraper, or you have budget and have the capacity to buy many servers and care less about performance.